The service support system provides the following:
- computing service,
- storage services,
- GRID systems, data transfer services ,
- distributed computing control systems ,
- information service (monitoring services, servers, storage, data transfer, information sites)
The Slurm workload manager is used to launch data processing tasks. The grid environment uses Advanced Resource Connector (ARC), a grid computing middleware. It provides a common interface for transferring computing tasks to various distributed computing systems and can include grid infrastructures of varying size and complexity.
The main data storage systems used are dCache and EOS. The afs storage system is used for user home directories, cvmfs is used to store project software ( cvmfs is a system for distributed access and organization of software versions for collaborations and user groups.
Computing Resources ( CE):
- Interactive cluster: lxpub [01-05] .jinr.ru
- User interface lxui [01-04] .jinr.ru (gateway for external connections)
- Computing farm.
SUM 2026Q2 (Old nodes have been decommissioned, and new ones have been introduced):
333 hosts
10324 cores
206329.91 HEPSCORE23
19.98 HEPSCORE23 average per core
2025Q1-Q4:
485 hosts 10356 cores 166788.4 HEP-SPEC06 16.11 HEP-SPEC06 average per core
Storage Systems (SE):
2025Q3-Q4:
EOS: 20445.18 TB EOS MPD: 7030.71 TB EOS SPD :7030.71 TB EOS ALICE : 1527.77 TB dCache : SE disks = 4845.52 TB for CMS: 2419.91 TB for ATLAS: 2425.61 TB AFS: ~12.5TB (user directories) CVMFS: 140TB 3 машины: 1 stratum0, 2 stratum1, 2 squid servers cache CVMFS EOSCTA 11PB Local & EGI @ dcache2 Total: 256.91 TB -It was liquidated at the request of the engineering department.
2025Q1:
EOS: 20230.69 TB (project and user data) MPD EOS: 7030.71 TB EOS-CTA: 11PB (collaboration, project data) EOS: ALICE 1527.79 TB dcache: 5047.56 TB (ATLAS+ CMS =4847.82 TB + Local&EGI 199.74 TB) openafs: 12.5 TB (user home directories, workspaces) CVMFS: 140 TB (storage of collaboration software versions) Tape robot: 91.5 PB
Software:
2025Q3-Q4:
Scientific Linux 7.9 и Alma Linux 9.6 EOS 5.2.32 dCache 8.2, EOSCTA cvmfs openafs SLURM 25.05.3 VOMS Alice VObox grid UMD4 + EPEL (currentversion) UMD4/5 + EPEL (currentversion) ARC-CE
NICA: FairSoft FairRoot MPDroot
2025Q2:
Support for the RHEL7 OS distribution and clones — SL7, SLC7, Centos7 has ended. On most CICC computers (Tier 2, Tier 1) we are switching to the OS Alma Linux 9 . This OS is almost a complete clone of RHEL9.
2025Q1:
CentOS Scientific Linux release 7.9, AlmaLinux9, EOS, cvmfs, openafs, slurm, VOMS, UMD, ARC-CE, RUCIO, ALICE VObox, WLCG standard program stack, BDII top, BDII site, glite, XROOTD, GCC, C++, GNU Fortran, dCache, Enstore CTA
==========================================================================================================================================
==========================================================================================================================================
2024
The launch of jobs for processing the CMS experiment data is carried out by 16-core pilots and all computing resources are available to them. The Slurm workload manager is used. The grid environment uses Advanced Resource Connector (ARC) – middleware for grid computing. It provides a common interface for transferring computing tasks to various distributed computing systems and can include grid infrastructures of varying sizes and complexities.
The main data storage systems used are dCache and EOS. The afs storage system is for user home directories. cvmfs is used to store software projects. (CVMFS is a system for distributed access and organization of software versions for collaborations and user groups) .
In 2024, a large amount of work was completed on the transition to the AlmaLinux 9 operating system (OS) due to the end of the life cycle of the CentOS 7 OS. A number of works were completed on the operation and development of the dCache-Enstore data storage system. Significant work has been done to modify Enstore. This includes converting code from python2 to python3, organizing parallel execution of requests for mounting/unmounting tapes in tape recorders, which significantly improved the time of these operations, and increasing the throughput of processing a large flow of requests for data transfer.
Computing Resources ( CE):
2023Q1-Q4: Total: 485 hosts 10356 cores 166788.4 HEP-SPEC06 16.11 HEP-SPEC06 average per core
Storage (SE):
8 old disk servers were removed, 4 new DELL R740 300TB each have been added SE disk has 4 servers; at EOS – 28.
As a result, we have at present:
EOS: 2023Q3= 23350 TB 2023Q2=21828.99 TB; 2023Q1=16582.35 TB; 2021/22=15.598 TB. ALICE @ EOS 1653.22 TB EOSCTA: 2023Q3=11000 TB AFS: ~12.5 TB (user home directories, workspaces) CVMFS: 140 TB (3 machines : 1 stratum0, 2 stratum1, 2 squid servers cache CVMFS ,VOs: NICA (MPD, B@MN, SPD), dstau, er, jjnano, juno, baikalgvd ..). dCache 2023Q2-Q4: ATLAS @ dcache 1939.25 TB CMS @ dcache 1994.18 TB Local & EGI @ dcache2 199.74 TB Total: EOS_(23350 TB + 1653.22 TB) + EOSCTA_(10000TB) + 12.5TB_(AFS) + 140TB_(CVMFS) + dCache_(1939.25 TB + 1994.18 TB + 199.74 TB) = 39288.89 TB
dCache: – Added: 2 servers ( Qtech QSRV-462402_3) = ~0.68 PB
EOS: – Added: 20 servers (Qtech QSRV-462402_4) . Sum(capacity): 22.353 PB
Software:
2023Q1: ОС: Scientific Linux release 7.9. EOS 5.1.9 (constantly changing) dCache 8.2 Enstore 6.3 for tape robots SPECall_cpp2006 with 32-bit binaries SPEC2006 version 1.1 . BATCH: Slurm 20.11 with adaptation to kerberos and AFS ALICE VObox grid UMD4 + EPEL (current versions) ARC-CE FairSoft FairRoot MPDroot
2017-2023Q1: 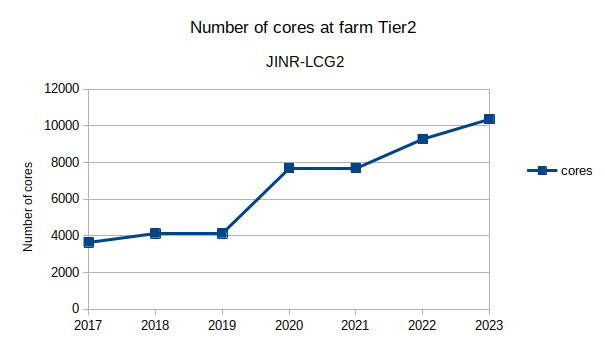
Archive:
Infrastructure and services of the Tier2 JINR-LCG2, 2024
Infrastructure and services of the Tier2 JINR-LCG2, 2023
Infrastructure and services of the Tier2 JINR-LCG2, 2021-22
Infrastructure and services of the Tier2 JINR-LCG2, 2020
Infrastructure and services of the Tier2 JINR-LCG2, 2019
The Infrastructure and Services of the Tier2, 2018
The Infrastructure and Services of the Tier2, 2017
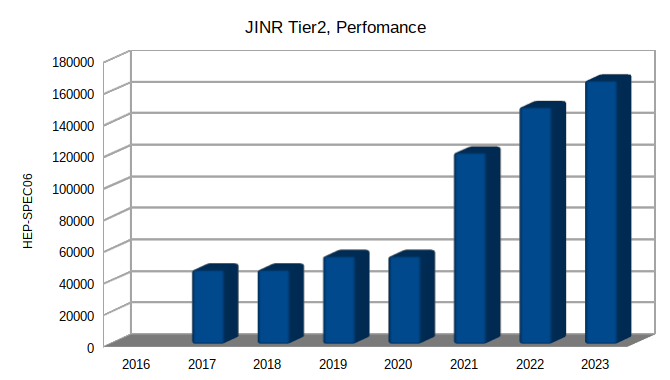
CE: 2023Q1-Q4: Total: 485 hosts 10356 cores 166788.4 HEP-SPEC06 16.11 HEP-SPEC06 average per core 2022: Total: 9272 cores 149938.7 HEP-SPEC06 a total performance 37484.7 HEP-kSI2k a performance per core 2021Q3: Total: 7700 cores 121076.99 HEP-SPEC06 a total performance 30269.25 HEP-kSI2k performance per core
CE: 2017 cores=3640; 46867 HEP-Spec06 2018 cores=4128; 55489 HEP-Spec06 2019 cores=4128; 55489 HEP-Spec06 2020 cores=4128; 55489 HEP-Spec06 2021 cores=7700; 121077 HEP-Spec06 2022 cores=9272; 149939 HEP-Spec06 2023 cores=10356;166788 HEP-Spec06