
The Common Muon and Proton Apparatus for Structure and Spectroscopy (COMPASS) experiment is a multipurpose experiment at CERN’s Super Proton Synchrotron (SPS). The experiment looks at the complex ways in which the elementary quarks and gluons work together to give the particles we observe, from the humble proton to the huge variety of more exotic particles.
A major aim is to discover more about how the property called spin arises in protons and neutrons, in particular how much is contributed by the gluons that bind the quarks together via the strong force. To do this the COMPASS team fire muons (particles that are like heavy electrons) at a polarized target.
Another important aim is to investigate the hierarchy or spectrum of particles that quarks and gluons can form. To do this the experiment uses a beam of particles called pions. In these studies, the researchers will also look for “glueballs” – particles made only of gluons.
2018.
About 240 physicists from 11 countries and 28 institutions work on the COMPASS experiment. The results will help physicists to gain a better understanding of the complex world inside protons and neutrons.
CERN IT constantly decreases access to LSF and Castor and forces experiments to use more intensively available Grid infrastructure built to service experiments on LHC. In the situation of limitations shown above, in 2014 an idea to start running COMPASS production through PanDA arose. Such transformation in experiment’s data processing will allow COMPASS community to use not only CERN resources, but also Grid resources worldwide. During the spring and summer of 2015 installation, validation and migration work is being performed at JINR.
COMPASS data taking started when mechanisms of distributed computing, such as Grid, were not yet available ( in summer 2002 and each data taking session contained from 1.5 to 3 PB of data). That is why computing model of the experiment is very conservative, centralised and relies on CERN ITs services, such as lxplus, Castor, lxbatch. Later, EOS was added to the data flow chain.
Below is a short and simplified description of implemented data flow, also presented on:
Fig. 1 COMPASS data flow.:
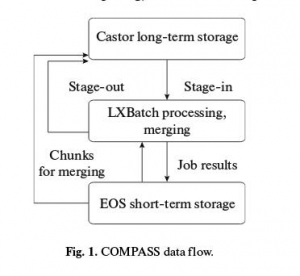
* all data is stored on Castor;
* data is being requested to be copied from tapes to discs before processing and then, once the data is ready, file moves to lxbatch for processing;
* the processing is done by the specific software;
* after processing results are being transfered either to EOS for merging or short-term storage or directly to Castor for long-term storage.
Current implementation of data-processing data flow has several limitations:
* data management is done by a set of scripts, deployed
under production account on AFS, and not organised as a commonly run system;
* execution of user analysis jobs and production jobs are
separated and managed by different sets of software;
* number of jobs which can be executed by collaboration at lxbatch is limited;
* available space on home of COMPASS’ production user at lxplus and Castor
is limited and strictlymanaged;
* Castor has a storage system which stores data on tapes and definitely not designed for random access reading from many users simultaneously;
* although COMPASS data f low has conditions to have distributed computing, due to historical premises it is implemented as a single-site processing which uses only one computing facility;
* absence of monitoring does not allow to track how and by whom the data is being used.