The goal of the STAR project (JINR participation) is to study the properties of nuclear matter at extreme densities and temperatures, to search for signatures of quark deconfinement and possible phase transitions in heavy ion collisions over a wide energy range at the Relativistic Heavy Ion Collider (RHIC). The research program also includes the study of the structure functions of quarks and gluons in collisions of transversely and longitudinally polarized protons.
The main JINR contribution to the STAR experiment is the manufacture and stable long-term operation of the barrel and end-cap electromagnetic calorimeters of the STAR facility. These detectors are the key elements for the polarization research program. Development of various software components. Simulation of asymmetries of direct photon and jet production in proton-proton collisions using the spin-dependent gluon distributions. Monte Carlo simulation of the effect of global polarization of lambda hyperons in the overlapping STAR / RHIC and NICA / MPD energy ranges.
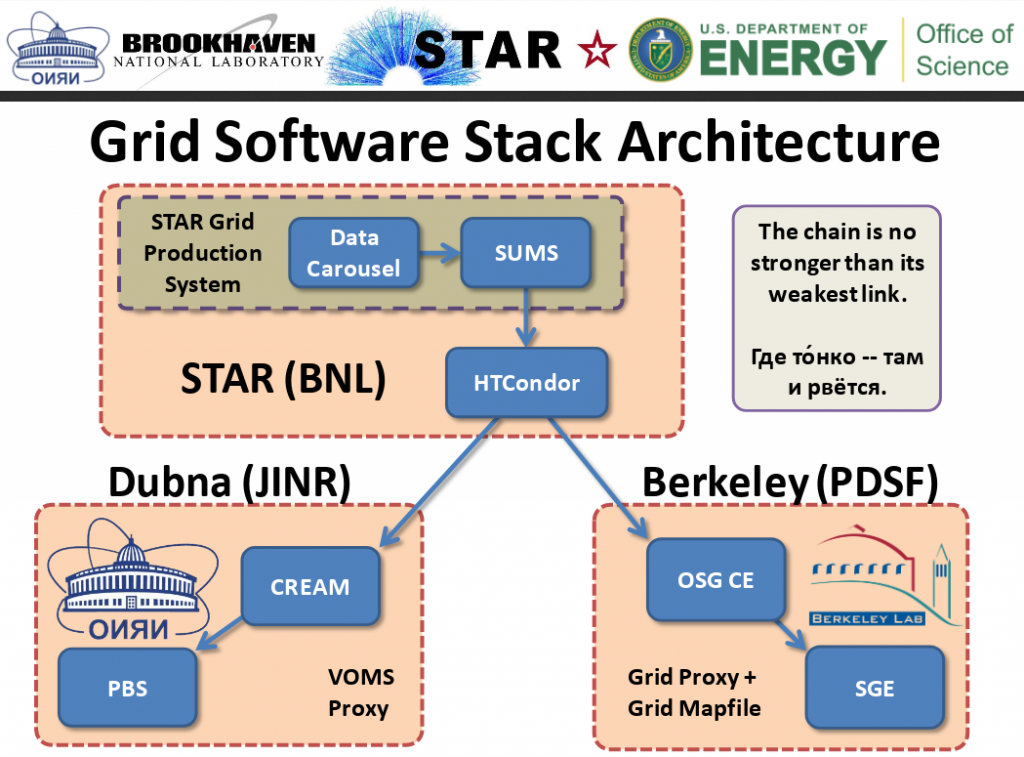
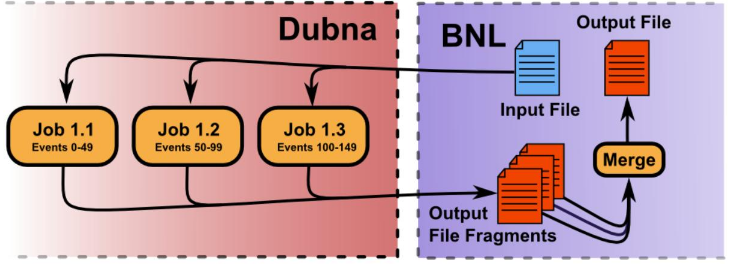
JINR‘s Tier2 infrastructure is used for processing data obtained during the STAR experiment (STAR–JINR end–to–end GRID production) and storage.
Space has been allocated for storage in the EOS 300TB system (2025Q3),
the SLURM system is used for data preparation and processing, 100 cores have been allocated per user for a total of 2000 cores. (2025Q3)
2018: Star at JINR.