
Эксперимент Common Muon и Proton Apparatus for Structure and Spectroscopy (COMPASS) является многоцелевым экспериментом в суперпротонном синхротроне CERN (SPS).
В эксперименте исследуются способы взаимодействия элементарных кварков и глюонов, в результате которых рождаются частицы от протона до огромного разнообразия более экзотических частиц.
Основная цель — узнать больше о том, как свойство, называемое спином, возникает в протонах и нейтронах, в частности, сколько внесено глюонами, которые связывают кварки вместе.
Другая важная цель — исследовать иерархию или спектр частиц, которые могут образовывать кварки и глюоны. Для этого в эксперименте используется пучок частиц, называемый пионами. В этих исследованиях физмки также будут искать «глюболы» — частицы, состоящие только из глюонов.
2018.
Около 240 физиков из 11 стран и 28 учреждений работают над экспериментом COMPASS. Результаты помогут физикам лучше понять сложный мир внутри протонов и нейтронов.
CERN IT постоянно снижает доступ к LSF и Castor и вынуждает эксперименты использовать более интенсивно доступную грид-инфраструктуру, построенную для обслуживания экспериментов на LHC.
В ситуации ограничений, показанных выше, было принято решение выбрать один из существующих инструментов распределенного анализа.
В 2014 возникла идея использовать PanDA систему управления производством и рабочей нагрузкой, изначально реализованной для удовлетворения потребностей ATLAS, для production COMPASS. Такое преобразование в обработке данных эксперимента позволит COMPASS использовать не только ресурсы CERN, но и ресурсы Grid по всему миру.
В течение весны и лета 2015 года в ОИЯИ были выполнены работы по установке, проверке и миграции ПО для COMPASS.
Сбор данных COMPASS начался, когда механизмы распределенных вычислений, такие как Grid, еще не были доступны. Вот почему компьютерная модель эксперимента очень консервативна, централизована и полагается на сервисы CERN ITs, такие как
lxplus, Castor, lxbatch. Позднее EOS была добавлена в цепочку потоков данных. Ниже приведено краткое и упрощенное описание реализованного потока данных.
Fig. 1 COMPASS data flow.:
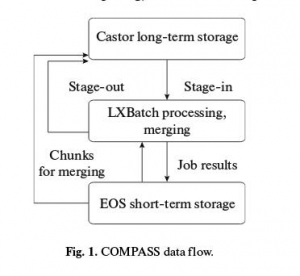
* все данные хранятся на Castor;
* данные запрашиваются для копирования с лент на диски перед обработкой, а затем, как только данные будут готовы, файл перемещается в lxbatch для обработки;
* обработка выполняется с помощью конкретного программного обеспечения;
* после обработки результаты передаются либо EOS для слияния, либо для кратковременного хранения, либо непосредственно в Castor для долгосрочного хранения.
Текущая реализация потока данных обработки данных имеет несколько ограничений:
* Управление данными осуществляется с помощью набора production account скриптов, расположенных в системе в AFS ;
* Выполнение пользовательских analysis jobs и production jobs разделены и управляются различным программным обеспечением;
* количество задач , которые могут выполняться в lxbatch, ограничено;
* доступное место для COMPASS в lxplus и Castor ограничено и строго контролируется;
* Castor имеет систему хранения, которая хранит данные на лентах и определенно не предназначена для чтения произвольного доступа у многих пользователей одновременно;
* хотя поток данных COMPASS имеет все условия для распределенных вычислений, из-за исторических предпосылок, он реализован как односайтовая обработка, которая использует только один вычислительный объект;
* отсутствие мониторинга не позволяет отслеживать, как и кем используются данные.
COMPASS (обычный мюонный протон)